It took about two months to complete this, but finally I’m proud to announce a new feature on the Pathfinder project: Artifact Crawler.
Up to now Pathfinder provided a maven plugin to populate the project with data to be analyzed.
Basic idea behind this is to make Pathfinder a tool to be integrated into a Continuous Integration chain, where each build would push its dependencies to the server.
But, using pathfinder in some real project, I realize that, if you do not have the tool fully integrated since long time, many steps of the projects inter-dependencies may be missing and you had to run the maven plugin on your own to integrate missing data.
So I added another approach to analyze project, not just a plugin to PUSH data, but the capability of Pathfinder itself to invoke the same process on artifact you already have on your maven repositories, local or remotes, to PULL the same data.
If you check my previous posts you surely know that Pathfinder Maven plugin is simply an extension of the default maven dependency-tree one, adding a store-tree goal which pushes all the informations to pathfinder server.
Sadly such plugin needs a pom file to be locally present to be analyzed, so I added another goal, the crawler one, which allow you to invoke the same store-tree process, but passing the artifact to be analyzed as plugin parameters.
This highly simplify integrating data, since you can retrieve informations directly from your repository without any additional source checkout, but it’s still a PUSH approach.
The next step was to integrate crawler goal directly into Pathfinder web interface.
Plugin execution was wrapped using maven-invoker API and exposed as a JSON rest service.
So now, if you just connected to your brand new Pathfinder server and want to start analyzing your project you just have to open the Graph Crawler accordion, fill in all details (in this sample we want to analyze the JUnit artifact) and hit the Crawl button
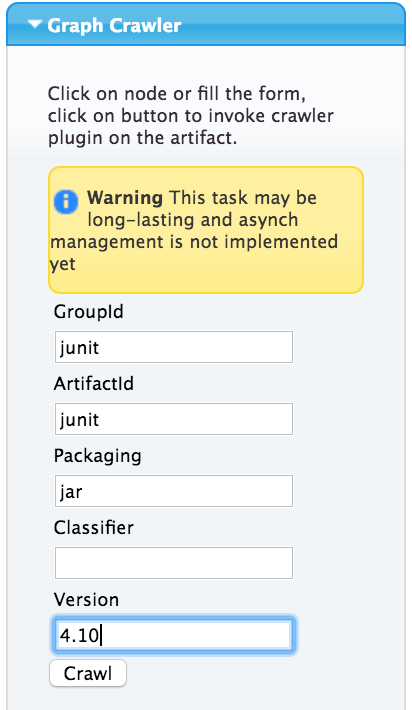
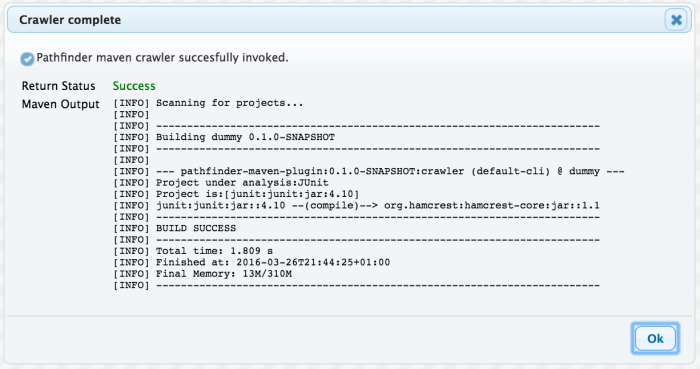
A please-wait dialog will appear and in few seconds (depending on the project complexity) it will change in a feedback dialog showing you the output of the crawler plugin exactly as if you would have invoked it from a command line.
Once you will close such dialog, the pathfinder graph will reload with the newly added artifact.
In our sample the graph it’s really simple since we have just another node in addition to the artifact we decided to analyze, but let’s go more in deep.
Suppose we want to extend our JUnit artifact analysis to hamcrest-core dependency as well; we just have to click on the artifact node and the Graph Crawler form will be automatically filled with node details, ready for a new submission.
But since we all love automation (and we all are very lazy), this time we will just double-click on the node and the crawler goal invocation will start immediately.
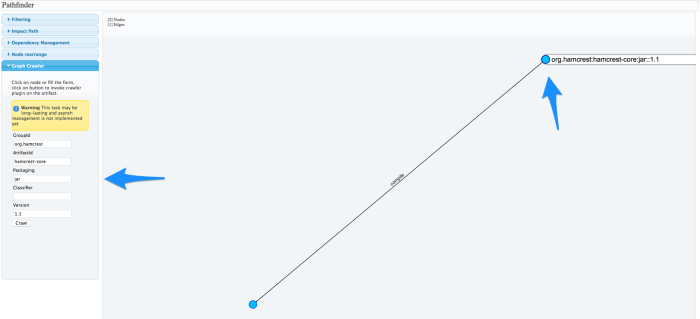
The crawler goal dialog will be shown again and once closed the graph will include all artifact from both our analysis.

We could continue our analysis more and more by simply going on with double-click on differente nodes to enrich our graph with additional dependencies.
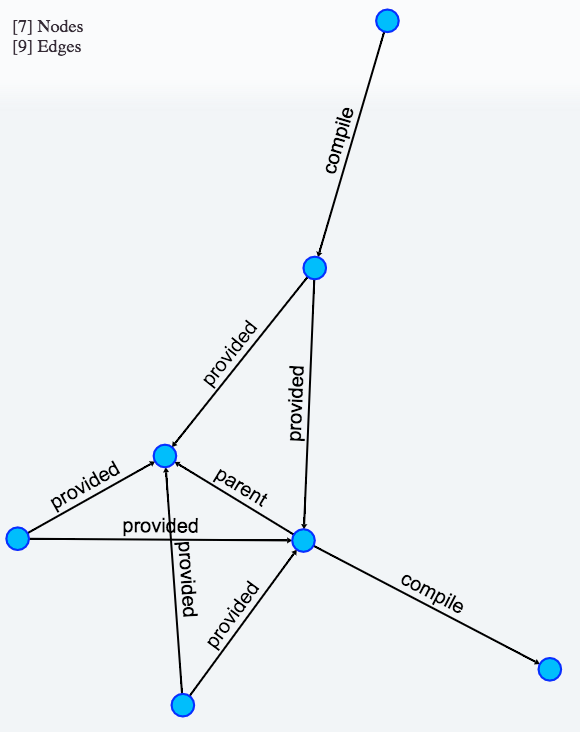
So basically with this new feature I started to add another approach to pathfinder application, not just PUSH integration within a CI chain (which still stay effective as a more global-view approach) but also a way to put only subset of your repository under the lens with a step-by-step PULL approach which make your analysis more detailed as you go further.
I think that such feature will greatly improve Pathfinder usability in early stage, when a full integration it’s not yet possible but you want to get as much benefit as possible from the dependencies analysis it can provide.
Next steps will probably be a load/save capability to store such in-deep analysis, and dome adjustments needed to manage analysis run on same project over time when dependency evolution is involved.
As usual you can find all details and source code at project’s GitHub or in previous Pathfinder blog posts

